kafka原理
2021年1月19日大约 7 分钟
消息中间件好处
- 解耦
- 异步
- 削峰
消息队列的通信模式
- 点对点。基于拉取或者轮询的消息传送模型,发送到队列的消息被一个且只有一个消费者进行处理
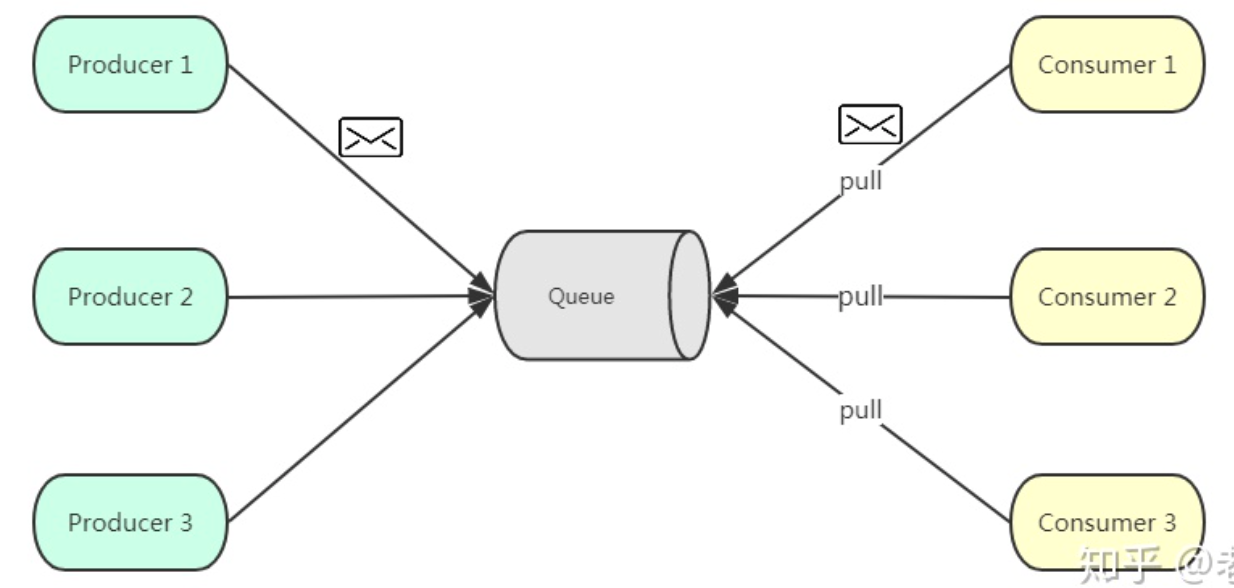
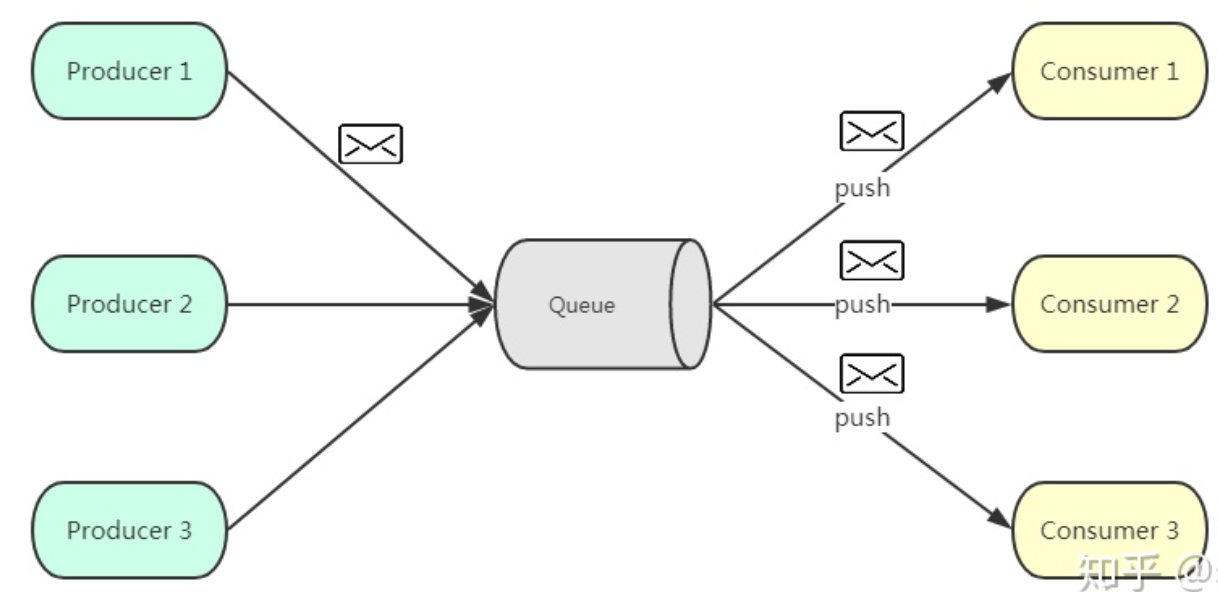
- 发布订阅
kafka 架构
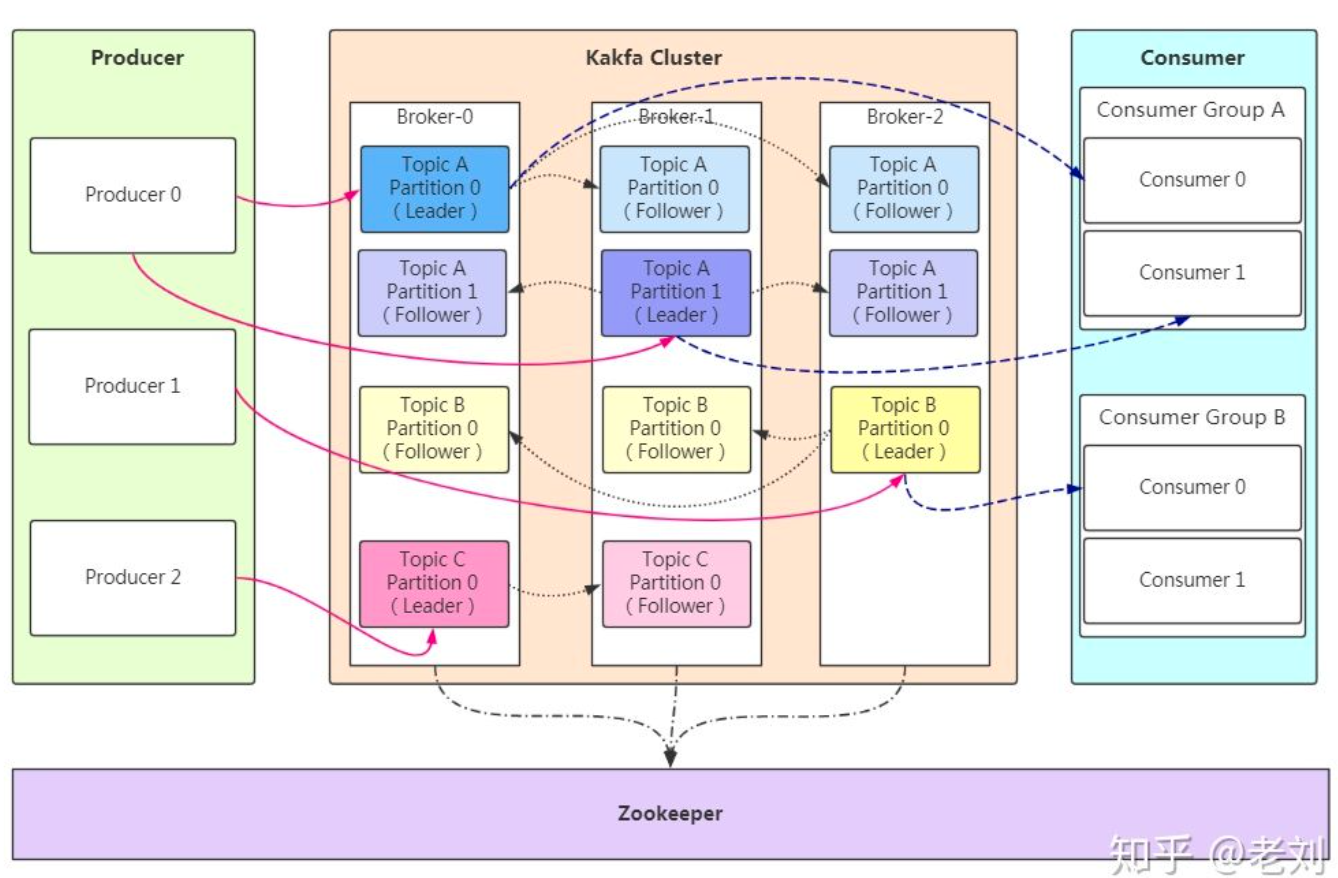
- 消费者组。同一个分区的数据只能被消费者组中的一个消费者消费;同一个消费者组的消费者可以消费同一个 topic 的不同分区的数据
- producer 采用发送 push 的方式将消息发到 broker 上,broker 存储后。由 consumer 采用 pull 模式订阅并消费信息
- partition 是文件,支持多个副本
优点
- 顺序读写磁盘。
- 顺序读写。按记录的逻辑顺序进行读、写操作的存取方法,即按照信息在存储器中的实际位置所决定的顺序使用信息,不容易删除数据。 2.在 Partition 末尾追加
- MMAP 内存映射文件。直接利用操作系统的 Page 来实现文件到物理内存的直接映射,完成映射后对物理内存的操作会被同步到硬盘上。
- 原理。可以像读写硬盘一样读写内存(逻辑内存),不必关心内存的大小
- 零拷贝。所有数据通过 DMA(直接内存访问)来进行传输,没有在内存层面去复制数据
- 数据批量处理
- kafka引擎读写行为特点
- 数据的消费频率随时间变化,越久远的数据消费频率越低
- 每个分区只有Leader提供读写服务
- 对于一个客户端而言,消费行为是线性的,数据并不会重复消费
工作流程分析
发送数据
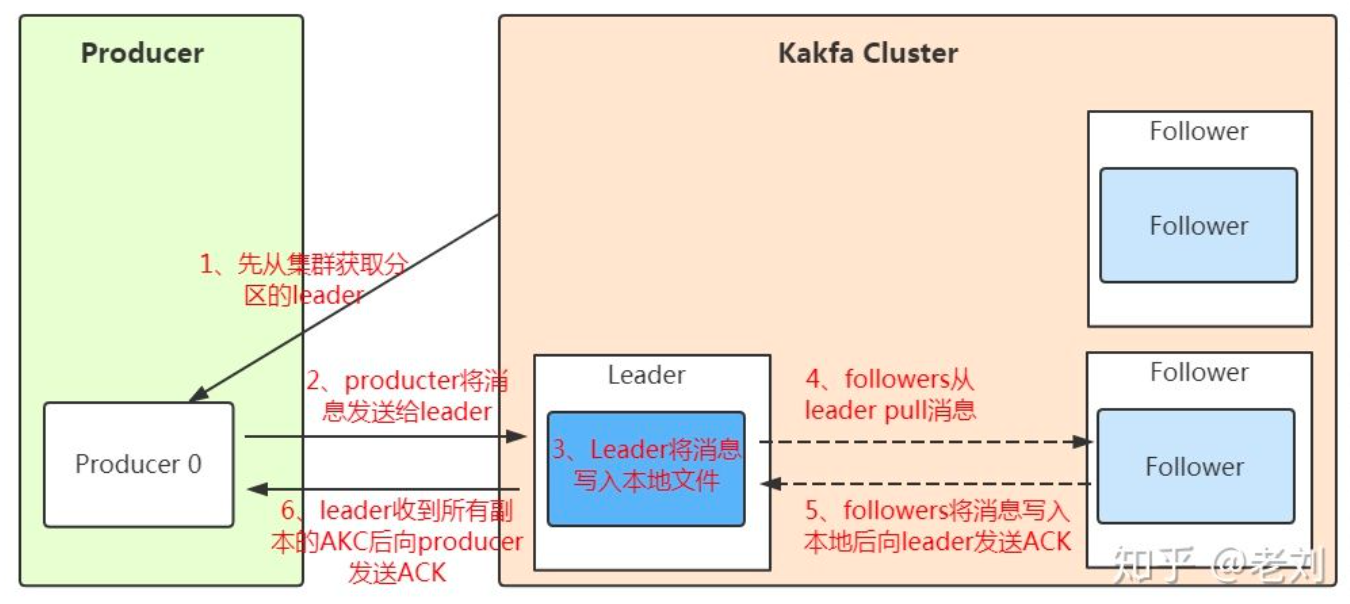
- 消息写入 leader 后,follower 是主动的去 leader 进行同步。
- producer 采用push 模式将数据发布到 broker,每条消息追加到分区中,顺序写入磁盘,保证同一分区内的数据是有序的。
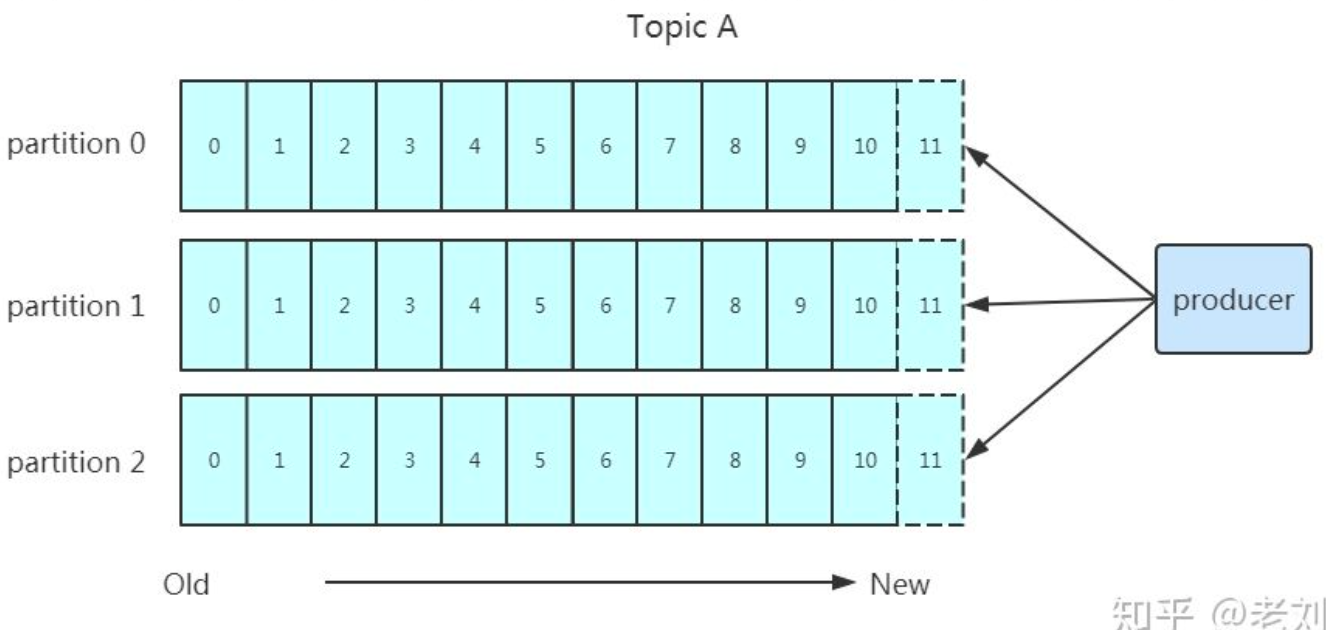
写入原则
- 按指定 partition 写入
- 按 key 的 hash 值算出 partition 写入【消息被均匀的分布到不同的 partition 中,才能实现了水平扩展】
- 没有设置 key,轮询选出一个 partition
消息可靠性保证
- 0。不需要等到集群返回,不能保证消息发送成功。
- 1。只要 leader 应答就可以发送下一条,只确保 leader 发送成功
- all[-1]。需要所有 follower 都完成 leader 的同步才会发送下一条,确保 leader 发送成功和所有的副本完成备份
CP【一致性和分区容错性】配置
request.required.acks=-1 min.insync.replicas = ${N/2 + 1} unclean.leader.election.enable = falseAP【可用性和分区容错性】配置
request.required.acks=1 min.insync.replicas = 1 unclean.leader.election.enable = falseProducer写入 Server端的I/O线程统一将请求中的数据写入到操作系统的PageCache后立即返回,当消息条数到达一定阈值后,Kafka应用本身或操作系统内核会触发强制刷盘操作
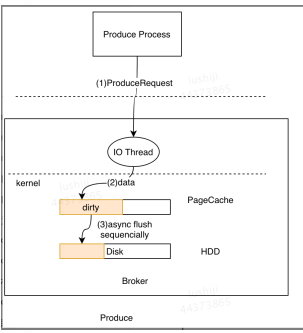
kafka 消息备份和同步
- 根据分区的多副本策略来解决消息的备份问题
- 名词解释
- ISR : leader 副本保持一定同步的 follower 副本, 包括 leader 副本自己,叫 In Sync Replica,最终会反馈到 zookeeper 上。
- AR: 所有副本 (replicas) 统称为 assigned replicas, 即 AR
- OSR: follower 同 leader 同步数据有一些延迟的节点
- HW: Highwater, 俗称高水位,它表示了一个特定的消息偏移量(offset), 在一个 parttion 中 consumer 只能拉取这个 offset 之前的消息(此 offset 跟 consumer offset 不是一个概念) ;
- LEO: LogEndOffset, 日志末端偏移量, 用来表示当前日志文件中下一条写入消息的 offset;
- leader HW: 该 Partititon 所有副本的 LEO 最小值;
- follower HW: min(follower 自身 LEO 和 leader HW);
- Leader HW = 所有副本 LEO 最小值;
- Follower HW = min(follower 自身 LEO 和 leader HW)。
- 副本
- 定义。在不同节点上持久化同一份数据,当某一个节点上存储的数据丢失时,可以从副本上读取该数据
- 分配规则。每个Broker都有均等分配Partition的Leader机会
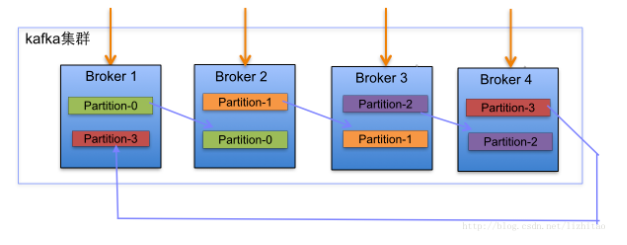
- 分配算法。
- 将所有N Broker和待分配的i个Partition排序
- 将第i个Partition分配到第(i mod n)个Broker上
- 将第i个Partition的第j个副本分配到第((i + j) mod n)个Broker上
- 消息接收
- 主要利用了操作系统的ZeroCopy机制,当Kafka Broker接收到读数据请求时,会向操作系统发送sendfile系统调用,操作系统接收后,首先试图从PageCache中获取数据
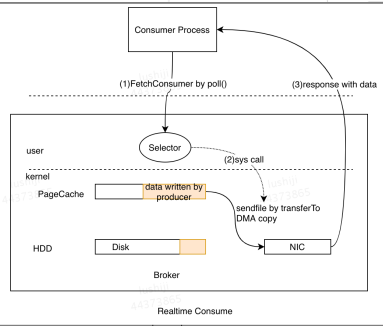
- 如果数据不存在,会触发缺页异常中断将数据从磁盘读入到临时缓冲区中,随后通过DMA操作直接将数据拷贝到网卡缓冲区中等待后续的TCP传输。
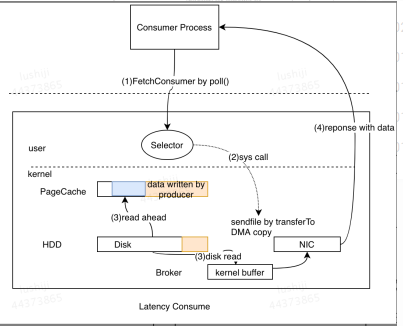
- 主要利用了操作系统的ZeroCopy机制,当Kafka Broker接收到读数据请求时,会向操作系统发送sendfile系统调用,操作系统接收后,首先试图从PageCache中获取数据
保存数据
顺序写入的方式将数据保存到磁盘
partition 结构
以文件夹的方式在服务器中存储
- 影响分区数量的因素
- 生产者的峰值带宽
- 消费者的峰值带宽
- 消费者的消费能力。同一个消费组里同一个分区只能被一个消费者消费
- 选取合适的分区数量
建议分区的数量一定要大于等于消费者的数量来实现最大并发
- Num=max(T/PT,T/CT)=T/min(PT,CT)
- Num:分区数
- T:目标吞吐量
- PT:生产者写入单个分区的最大吞吐量
- CT:消费者从单个分区消费的最大吞吐
- 分区数量=T/PT 和 T/CT 中的
- PT 影响的因素:批处理的规模、压缩算法、确认机制、副本数等有关
- 信息参考
- 单个分区可以实现消息的顺序写入
- 单个分区只能被同消费组的单个消费者进程消费
- 单个消费者进程可同时消费多个分区
- 分区越多,当 Leader 节点失效后,其他分区重新进行 Leader 选举的耗时会越长
- 分区的数量是可以动态增加的,只增不减,但增加会出现 rebalance 的情况
message 结构
- offset。占 8byte 的有序 id 号,唯一确定每条消息在 partition 内的位置
- 消息大小
- 消息体。
文件存储设计特点
- Kafka把topic中一个parition大文件分成多个小文件段,通过多个小文件段,就容易定期清除或删除已经消费完文件,减少磁盘占用。
- 通过索引信息可以快速定位message和确定response的最大大小。
- 通过index元数据全部映射到memory,可以避免segment file的IO磁盘操作。
- 通过索引文件稀疏存储,可以大幅降低index文件元数据占用空间大小。
存储策略
- 基于时间,默认 7 天;
- 基于大小,默认 128MB;
消费数据
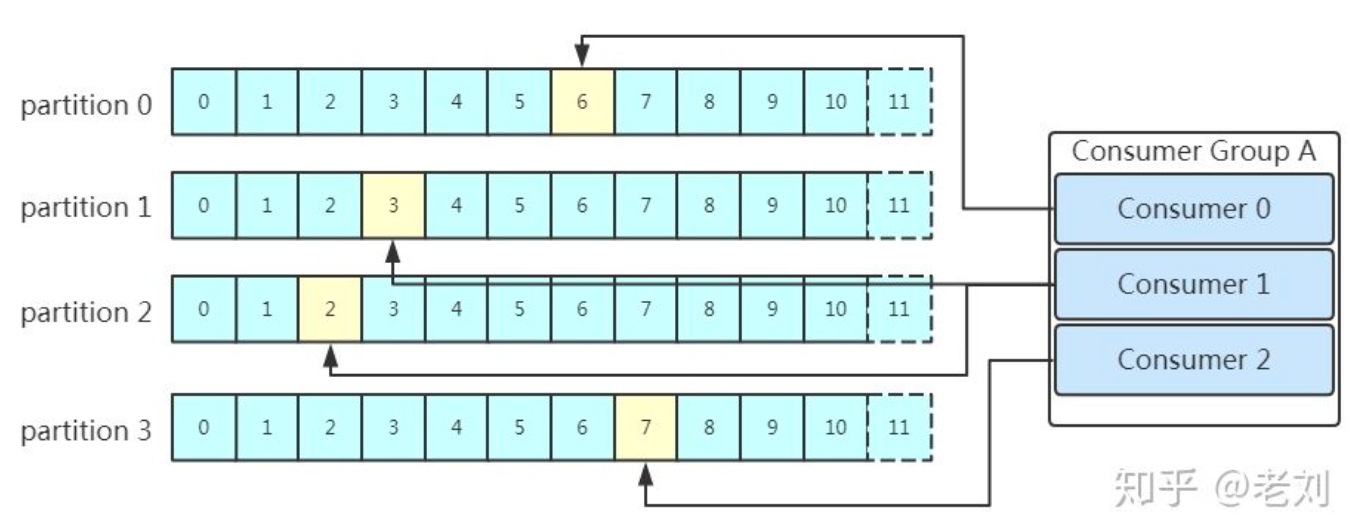
- 点对点模式。由消费者主动去 kafka 集群拉取消息
- 消费者组 consumer 的数量与 partition 的数量一致
消费场景
- AutoCommit(实际消息会丢)
enable.auto.commit = true
// 自动提交的时间间隔
auto.commit.interval.ms
- 手动 commit(at least once,消息重复,重启会丢)
// oldest:topic里最早的消息,大于commit的位置,小于HW,也受到broker上消息保留时间和位移影响,不保证一定能消费到topic起始位置的消息
sarama.offset.initial (oldest, newest)
// 主题偏移量日志文的保留时长,默认设为1440s
offsets.retention.minutes
消费原理
- 数据异步批量的存储在磁盘中,采用批量刷盘的做法进行,即按照一定的消息量和时间间隔进行刷盘。先存储到页缓存(Page cache)中,按照时间或者其他条件进行刷盘,或通过 fsync 命令强制刷盘。做不到不丢失消息,只能通过调整刷盘机制的参数缓解该情况
- 通过 ack 的方式来处理消息丢失的情况
指令
- 创建 topic
./kafka-topics.sh --create --topic dev2wx --replication-factor 1 --partitions 2 --zookeeper master:2181
- 查看 topic
./kafka-topics.sh --list --zookeeper master:2181
- 查看 consumer list
./kafka-consumer-groups.sh --bootstrap-server master:9092 --list
./kafka-topics.sh --list --zookeeper master:2181 4. 消费积压情况
./kafka-consumer-groups.sh --bootstrap-server master:9092 --describe --group logstash